
De dataset die we voor deze blogpost gebruiken is er eentje met 27156 rijen en bevat de Engelstalige naamgevingen van enkele landen. In de dataset zijn er initieel 146 unieke waarden aanwezig, die we doorheen deze blogpost zullen trachten op te schonen. Het is dan ook opmerkelijk dat door onderstaande stappen te volgen, we onze data kunnen reduceren tot 122 unieke waarden.
Installatie en opstarten OpenRefine
Ga naar http://openrefine.org
Wanneer Java reeds geïnstalleerd is op uw computer: Kies 'Windows Kit'
Zo niet: Kies 'Windows kit with embedded Java'
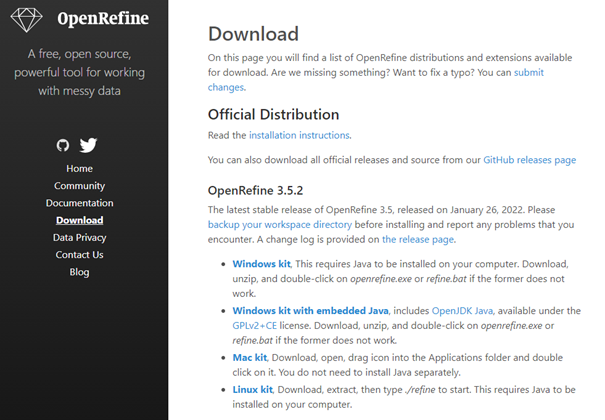
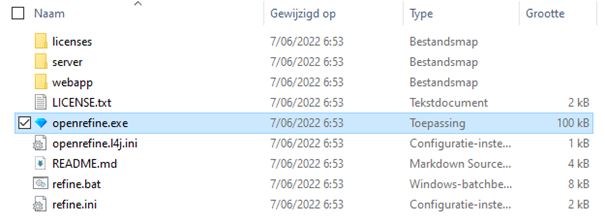
Download het zip bestand en pak deze ergens uit. Open vervolgens de ‘openrefine’ en klik op openrefine.exe om deze op te starten.
Gebruik van OpenRefine
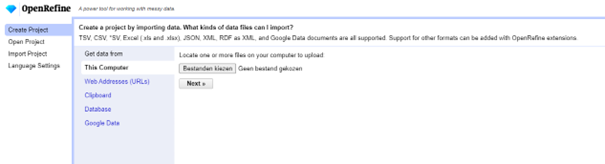
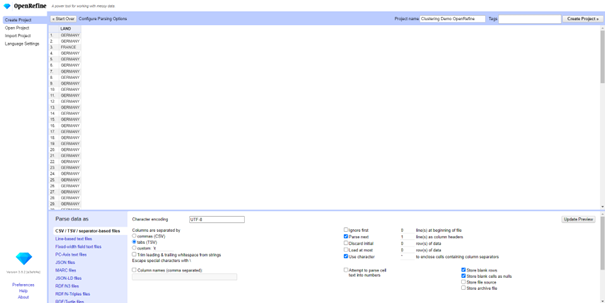
Geef een toepasselijke project naam en druk vervolgens op ‘create project’
<info>
Om meer rijen te zien kan je op het aantal rijen om weer te geven veranderen naar een grotere waarde: in de afbeelding hieronder staat deze bvb op 500.
Klik vervolgens op de kolom waarvan u de datakwaliteit van wilt verhogen. In ons geval is er maar 1 kolom aanwezig in de dataset, namelijk LAND. Ga in het dropdown menu naar ‘Edit Cells’ en kies vervolgens de optie ‘Cluster and edit…’
Er zijn verschillende vergelijkingsmethoden in OpenRefine aanwezig om tekstitems te vinden die op elkaar lijken maar niet identiek zijn. De twee strings "Cameroun” en "Cameroon" verwijzen bijvoorbeeld zeer waarschijnlijk naar hetzelfde land maar hebben enkel een net iets wat andere schrijfwijze.
Het groeperen van deze tekstitems wordt ook wel eens ‘clustering’ genoemd, en is een term waar ook OpenRefine gebruik van maakt in zijn software. In OpenRefine wordt er van uit gegaan dat elke bewerking op een clustering, altijd moet goedgekeurd worden door de gebruiker. Om de gebruiker te helpen, geeft OpenRefine ook steeds een voorstel waarvan hij denkt dat dit de data opschoont. De gebruiker kan vervolgens selecteren welke versie te behouden en toe te passen op alle overeenkomende cellen (of de gebruiker typt zijn eigen versie in).
Daarnaast zal OpenRefine achter de schermen een aantal ‘data cleaning’-operaties uitvoeren om zijn analyse te kunnen doen. Inzicht in die verschillende opruimingen achter de schermen kunnen de gebruiker helpen te kiezen welke clustermethode nauwkeuriger en effectiever zal zijn. Daarvoor kan u terecht binnen enkele andere van onze blogposts.
Echter, de gebruiker hoeft de details achter elke clustermethode niet te begrijpen om ze met succes op uw gegevens toe te passen. De volgorde waarin deze methoden in de interface en op deze pagina worden gepresenteerd is de volgorde die door OpenRefine wordt aanbevolen - beginnend met methoden met zeer strikte regels, tot methoden die wat lakser zijn en die dus wel meer menselijke supervisie vereisen om correct toe te passen.
OpenRefine biedt een verscheidenheid aan clustering methoden:
- Key Collision
- fingerprint
- ngram-fingerprint
- metaphone3
- cologne-phonetic
- Daitch-Mokotoff
- Beider-Morse
- Nearest Neighbor
- levenshtein
- ppm
Key collision : fingerprint:
Deze methode heeft de minste kans om ‘false positives’ terug te geven en vormt zodus een goede methode om van start mee te gaan. We spreken van een ‘false positive’ wanneer OpenRefine aangeeft dat twee strings waarschijnlijk hetzelfde zijn, terwijl dat in werkelijkheid niet zo is.
Achter de schermen worden de gegevens opgeschoond door volgende acties toe te passen:
- witruimte omzetten in enkele spaties
- zet alle hoofdletters in kleine letters
- interpunctie verwijderen
- diakritische tekens (bv. accenten) uit karakters verwijderen
- splits alle reeksen (woorden) op en sorteer ze alfabetisch (dus "Zhenyi, Wang" wordt "wang zhenyi").
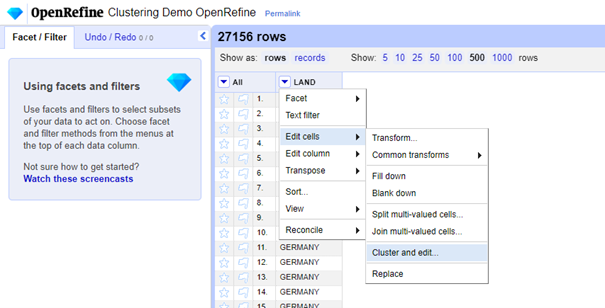
In onderstaande afbeelding is zo te zien dat het tekstitem ‘POLAND’ en ‘¿POLAND’ met deze methode gevonden wordt door het verwijderen van diakritische tekens.
Om het record met ‘¿POLAND’ te vervangen met ‘POLAND’, hoeft de gebruiker enkel de ‘Merge?’ checkbox aan te vinken en OpenRefine heeft reeds op basis van de dataset het voorstel gedaan om ‘POLAND’ te kiezen als vervangwaarde.
Om de wijziging toe te passen, klikt de gebruiker tot slot op de ‘Merge Selected & Re-Cluster’
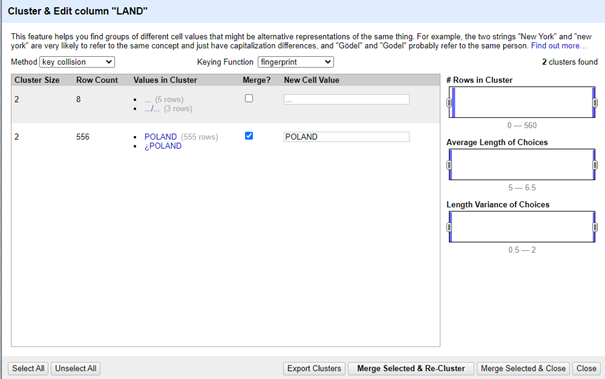
NGram-Fingerprint:
N-gram fingerprinting laat de gebruiker toe de ‘Ngram-size’ in te stellen en afhankelijk van welk getal de gebruiker kiest, zal deze verschillend gedrag tot gevolg hebben:
Bijvoorbeeld, een 1-gram vingerafdruk zal eenvoudig alle letters in de cel in alfabetische volgorde zetten - door segmenten te maken van één karakter lang. Een 2-grams vingerafdruk zal alle segmenten van twee karakters vinden, duplicaten verwijderen, ze alfabetiseren, en ze terug samenvoegen (bijvoorbeeld, "banaan" genereert "ba an na aa an," wat "aanbana" wordt).
Dit kan helpen bij het matchen van cellen met typefouten of onjuiste spaties (zoals het matchen van "Verenigde Staten" en "Verenigdestaten", wat fingerprinting zelf niet zal identificeren omdat het woorden scheidt). Hoe hoger de n-waarde, hoe minder clusters zullen worden geïdentificeerd. Let bij 1-grammen op verkeerd gematchte waarden die bijna-anagrammen van elkaar zijn (zoals "Wellington" en "Elgin Town").
Voor de dataset waar we in deze blogpost van gebruik maken, zijn de beste resultaten terug te vinden door de Ngram Size gelijk te stellen aan één.
Vervolgens passen we opnieuw de stappen toe we reeds eerder toepasten in de eerste fingerprint methode.
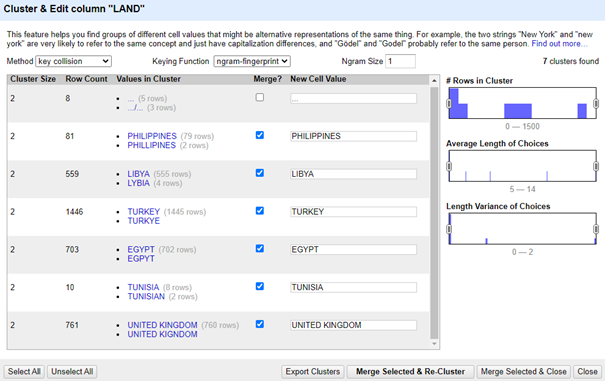
Fonetisch Clusteren
De volgende vier methoden zijn fonetische algoritmen: ze identificeren letters die hetzelfde klinken als ze hardop worden uitgesproken, en beoordelen op basis daarvan tekstwaarden (zoals weten dat een woord met een "K" een fout-type kan zijn van een woord met een "C"). Ze zijn zeer geschikt om fouten op te sporen die worden gemaakt doordat men de spelling van een woord of naam niet kent nadat men het hardop heeft horen uitspreken. Aangezien onze data betrekking heeft tot plaatsnamen, is het dan ook te verwachten dat deze methoden tot mooie resultaten kunnen leiden.
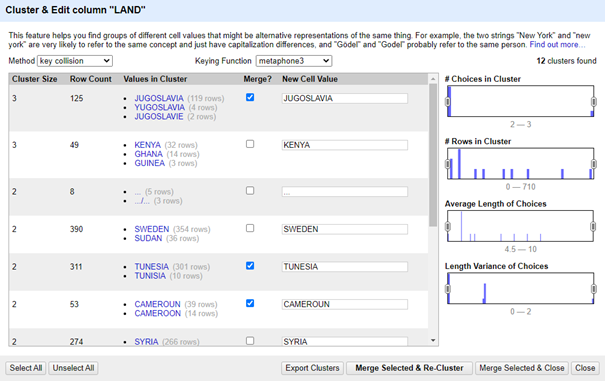
Methaphone 3:
Metaphone3 fingerprinting is een fonetisch algoritme specifiek voor de Engelse taal. Bijvoorbeeld, "Reuben Gevorkiantz" en "Ruben Gevorkyants" hebben dezelfde fonetische vingerafdruk in het Engels.
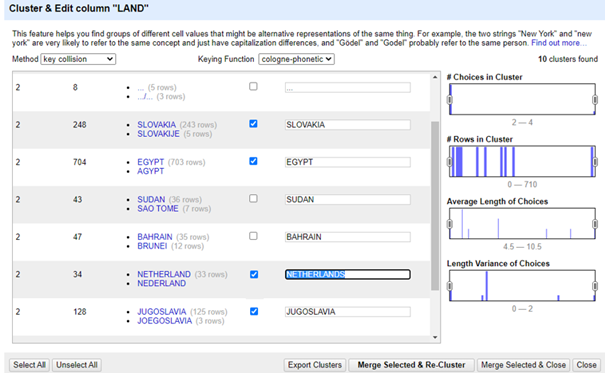
Cologne phonetic:
Cologne fingerprinting is een ander fonetisch algoritme, maar dan voor de Duitse/Nederlandse uitspraak.
Interessant om aan te kaarten in onderstaande afbeelding, is dat het belangrijk is om toch de suggestie die OpenRefine maakt te valideren. Oorspronkelijk werd ‘NETHERLAND’ voorgesteld, op basis van de manier waarop ‘Nederland’ is onze dataset werd voorgesteld, maar eigenlijk weten we dat de Engels vertaling ‘Netherlands’ is en passen we dit idealiter manueel aan.
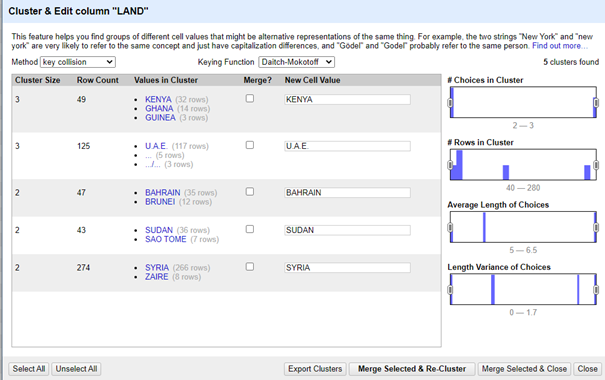
Daitch-mokotoff:
Daitch-Mokotoff is een fonetisch algoritme voor Slavische en Jiddische woorden.
Aangezien onze dataset hoofdzakelijk uit Engelse woorden bestaat, is het dan ook niet te verwonderen dat er weinig relevante clusters worden gevonden.
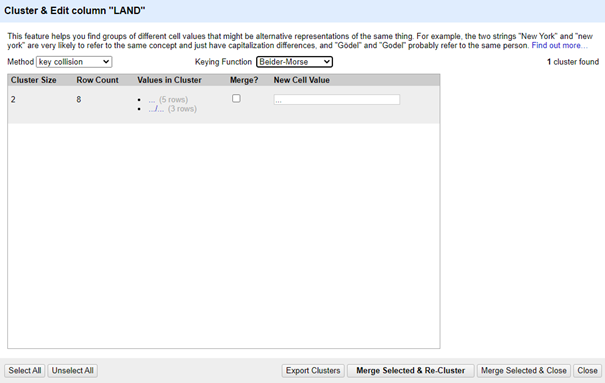
Beider-Morse:
Baider-Morse is een versie van Daitch-Mokotoff die zelfs nog net iets strengere regels hanteert. In de dataset van deze blogpost werd er dan ook geen enkele relevante cluster gevonden.
Nearest Neighbour algoritmen :
Over het algemeen zijn Neighbour-clusteringmethoden langzamer dan fingerprintmethoden.
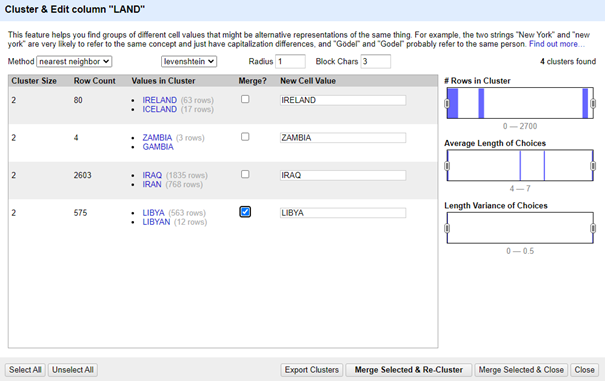
Zij staan de gebruiker toe een radius in te stellen - een drempel voor overeenkomen of niet overeenkomen. OpenRefine gebruikt eerst een "blocking" methode, die waarden sorteert op basis van of ze een bepaalde mate van overeenkomst hebben (de standaardwaarde is "6" voor een tekenreeks van zes identieke tekens) en dan de nearest-neighbour operaties uitvoert op die gesorteerde groepen.
Er wordt aangeraden om het bloknummer op minstens 3 in te stellen, en het dan te verhogen als het algoritme strenger moet zijn.
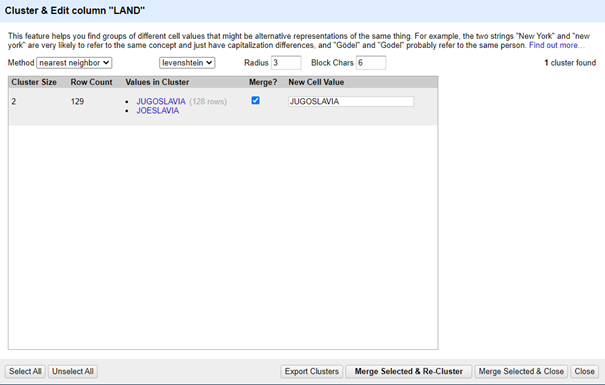
Het vergroten van de straal zal de overeenkomsten lakser maken, omdat grotere verschillen zullen worden geclusterd. Wanneer men Block Chars verhoogt bekomt men minder clusters.
Levenshtein: Radius 1 Block Chars 6: <Default>
Met aanpassingen -> Block Chars = 3
Met aanpassingen -> Block = 6 <default> en Radius = 3
Extra: Het behandelen van ongeldige records
Wanneer we alle clusteringsmethoden hebben toegepast op onze dataset, en we merken dat er ‘ongeldige’ records aanwezig zijn in de data, kan het interessant zijn om deze te vervangen door lege cellen. Op die manier kunnen andere tools in de toekomst hier ook verder op in spelen.
Vergelijking van initiële en opgeschoonde dataset.
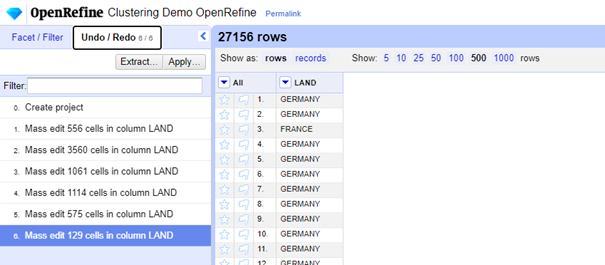
We kunnen de historiek van onze acties terugvinden in de Undo/Redo. We kunnen constateren dat onze acties meer dan 7000 cellen heeft beïnvloed en dat onze data kwaliteit aanzienlijk is verbeterd.
We kunnen dit ook valideren door te kijken naar de unieke waarden die terug te vinden is de kolom:
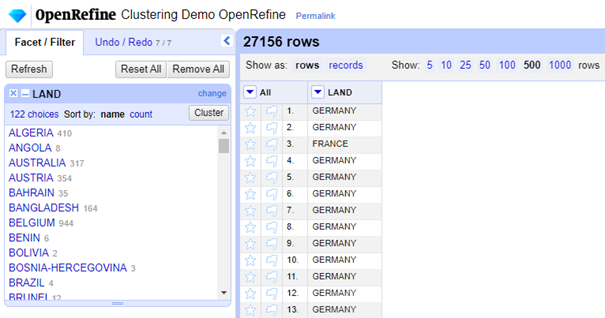
Terwijl dit oorspronkelijk het volgende was:
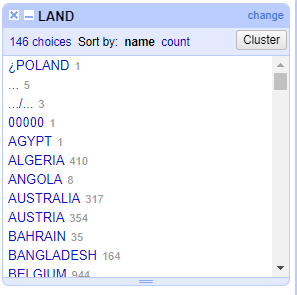
Voorlopig zijn de aanpassingen enkel aangebracht binnen het hoofdgeheugen van OpenRefine kiezen we rechtsboven voor ‘Export’.
Om onze aanpassingen op te slaan:

- Login of registreer om te reageren